
Debugging Move Generation and Optimization
Building a Chess Engine - Part 4

I spent the last week finishing the move generation, debugging it and making some changes that where needed to make everything work. The changes aren't too exciting since they "just" make everything work without implementing something completely new. So in this post I'll summarize the many changes that happened over the past week.
Attacks
Castling was still missing from my move generation, so this was the first thing I wanted to implement. To do this, one needs to check if the squares the king castles through are attacked. To do this, I wrote a new class to compute the attacked squares.
This is very similar to the normal move generation. The differences are only that one doesn't need to remove attacks on squares occupied by friendly pieces. Also the pawn attacks are much easier to compute than all possible pawn moves.
The castling itself is straightforward to implement. I used the leading bit in the move encoding to indicate if the move was castling and moved the king and rook accordingly.
Unmaking moves
To calculating different moves from one starting position, one could make a copy of the starting position for each move that can be played. But this takes a lot of time and memory, so chess engines usually "unmake" moves when calculating different branches from a position. This means that they calculate one variation, then backtrack their steps and start with the next variation when they reached the starting position.
The implementation is a bit tricky since moves aren't reversible. You can't tell if it was a capture (in the for engines usual UCI notation), which piece was captured and other information like castling rights and the en-passant square also can't be deduced. So I first added the following struct to keep track of this information:
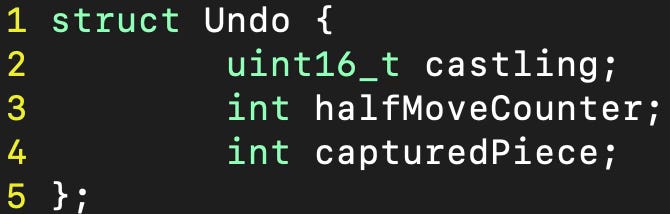
This struct will then be populated with the information of a board before a move is played and afterwards it's used to revert the move. I used it in the following way:
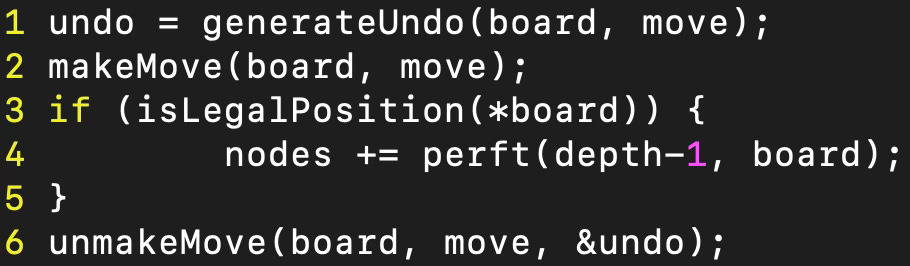
Debugging move generation
To find mistakes in the move generation, one can use the perft function. This computes all legal moves in a position up to a given depth. Then one can either look at some reference tables or use Stockfish to compute the legal moves for any position.
I first looked at the legal moves from the starting position and compared it to a table with the correct number of moves. After I got the correct number of moves for the first couple of moves, I looked at specific positions with Stockfish. When I noticed that the number of moves was incorrect, I drilled down to find the specific instance where the error happens.
The bugs where mostly typos or scenarios I didn't consider. For example, I didn't remove the castling rights after a rook got captured on its starting square. Also some bugs where harder to find because the engine introduced a mistake into the position. Take a look at the following example where my engine displayed amazing creativity:

One of the moves the engine came up with was castling short which is fine, but when the engine actually played the move, it lead to the following position:

A mixture of typos and castling logic lead to the black rook landing on c6.
This bug was somewhat hard to identify because it looked like my engine played a legal move and if I looked at the position after castling correctly, everything was fine.
Performance optimizations
When I first ran the perft from the starting position, I was very surprised with how slow my move generation was. The speed was only around 200k nodes per second. As a comparison, Stockfish has around 900k nodes per second on my laptop which includes the evaluation and search function. So I knew I needed to do quite a bit of optimizations, just to test the move generation at an acceptable speed.
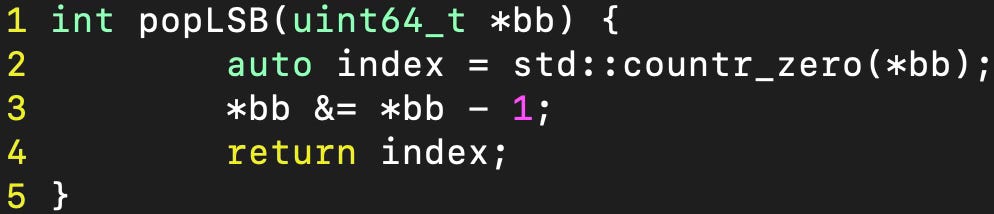
The first thing I did was rewriting the popLSB function since it's used quite often and I knew that there is a better way to remove the final bit. Here is what it looks like now:
Next I noticed that the slowest part of the engine is the move generation for sliding pieces. First I rewrote the function to reverse a bitboard which lead to a huge speedup.
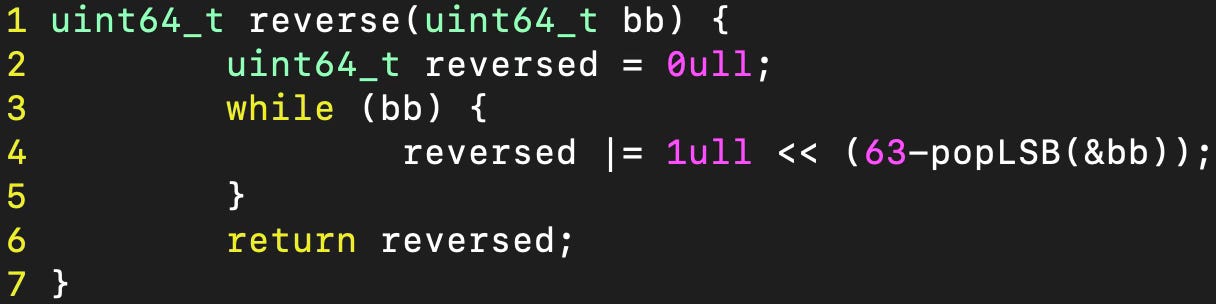
This approach is so much faster because the old function always looped through all 64 bits. Now we only look at the 1s and since bitboards are generally very sparsely populated, there are way fewer iterations.
Then I also made some changes to the generation of the sliding moves to reduce the size of the bitboards which needed to be reversed. Finally I used more pointers to the current board which was also a little speedup. Here is how the speed of the engine improved with these changes:
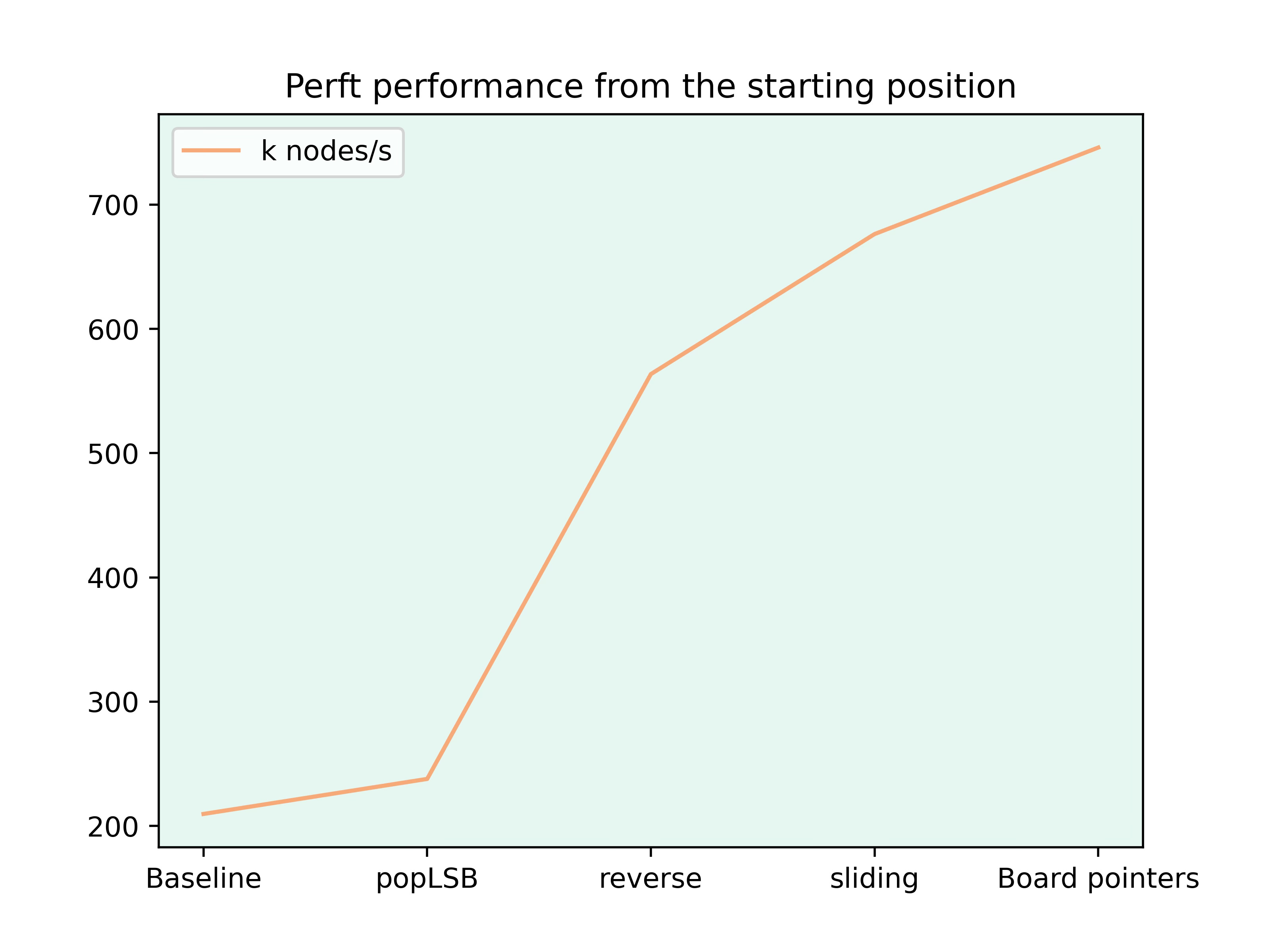
The generation of sliding moves is still the slowest part and I'll look into magic bitboards in the future. But for now I think that the performance should be good enough to implement the evaluation and search. So you can look forward to some more exciting changes in the next week.
Or is it perft vs perft. You control the tree expansion to be full legal to certain go depth. All node being only checked for terminal outcomes or intput depth. I might have not parsed well. But if this last thing, then yes. SF perft would be same tree growth. and I don't know the details of how you count the node there, but if UCI imposes a perf mode for engines. Then then what ever node defition it would be comparable, and supporting your argument, that somehow it is the lowest level move generation sub-module (I am guessing from my past SF understanding, I might not be having the details of move preordering etc. .right. and move generation conceptual start and end in the search module. been a while if I ever did.
I have a question about node terminology in engine outputs. Is it all nodes or only the leaf nodes (getting a static evaluation). I am asking because I just read that you were comparing SF and your move generation. But SF measure is from the UCI ouput, I get confused if that include interior nodes. As if you are builder the partial tree search like SF type of engine, the move generation is "uptree" frome leaf nodes. I have not follow the detail since you entered the move part. I might have lost track of your node typing. (programming wiki has more than one, depending on the heuristic names. but with AB pruning you already have types. I am more interested with the disctinction between interior nodes (always interior, as iterative deepening (are you using that yet) would have more nodes having been evaluated as leafs, than in the godepth (UCI input depth model of trea search stop) maximal iterative depth), one might think is only looking an interior nodes of such full PV (or what you call the full partial branches of your search tree). If and when I make sense. I would be curious about how you would keep classifying nodes, if my coarse root node, leftmost mode in one branch of the many candidates being exploered, on each branches, interior nodes, and the leaf nodes. AB pruning would add more types. and iterative deepening would allow a whole zoo of foward pruning heuritics.
so if SF is only giving the leaf nodes in its node count, and you are looking at all interior nodes in move generation and rewinds, you might be looking at SF agreesive tree growth pruning.