
Predicting the Winner of Tournaments
Using game predictions to predict the outcome of a tournament

In my previous post, I looked into the prediction of the outcome of a single chess game, with the bigger goal to be able to predict the winner of a tournament. This is what I’m going to write about in this post.
Evaluating the game prediction
One thing I omitted from my last post was a test of how well the game prediction worked over the course of a tournament.
To test this, I looked at the super tournaments played in the last 2 years and calculated the difference between the points each player actually scored in the tournament to my prediction of the points. To make tournaments with different lengths comparable, I normalised the length of each tournament to be 9 rounds.
Below you can see the relative number of players for different point errors over the course of a tournament.
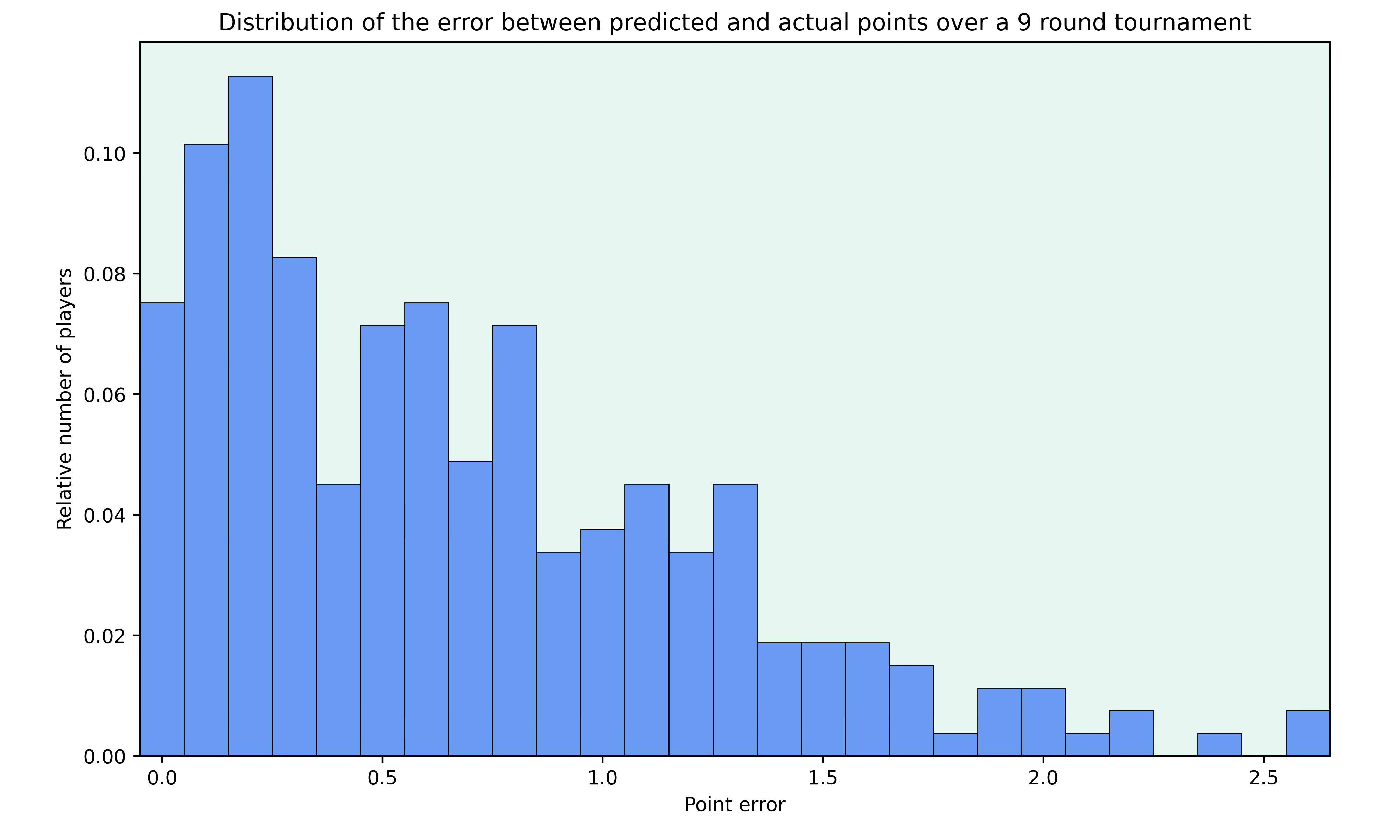
I think that the results are quite good, with most deviations being below 1 point. The mean of the point error per player over 9 rounds is about 0.61 and 75% of players are within 1.1 points of their predicted result.
Predicting a tournament winner
Getting the expected number of points a player should score in a tournament is pretty easy, if we assume that all games are independent (more on that later). We can just predict the games individually and add up the points. However, knowing the expected number of points doesn’t say much about the winning chances of each player.
To get the winning chances of each player in a tournament, we can use Monte Carlo simulations of the tournament. The idea behind this is to simply simulate the tournament many times, using our result prediction to predict the result of every game, and then count how often each player finished first. As we increase the number of simulations, the win probabilities for all players converge to their expected values.
To test the number of simulations needed for a chess tournament, I looked at the recently finished tournament in Wijk aan Zee (you can check out my visual recap of the tournament here). Below are the probabilities to finish clear first for the top 6 rated players in the tournament, depending on the number of simulations I ran.
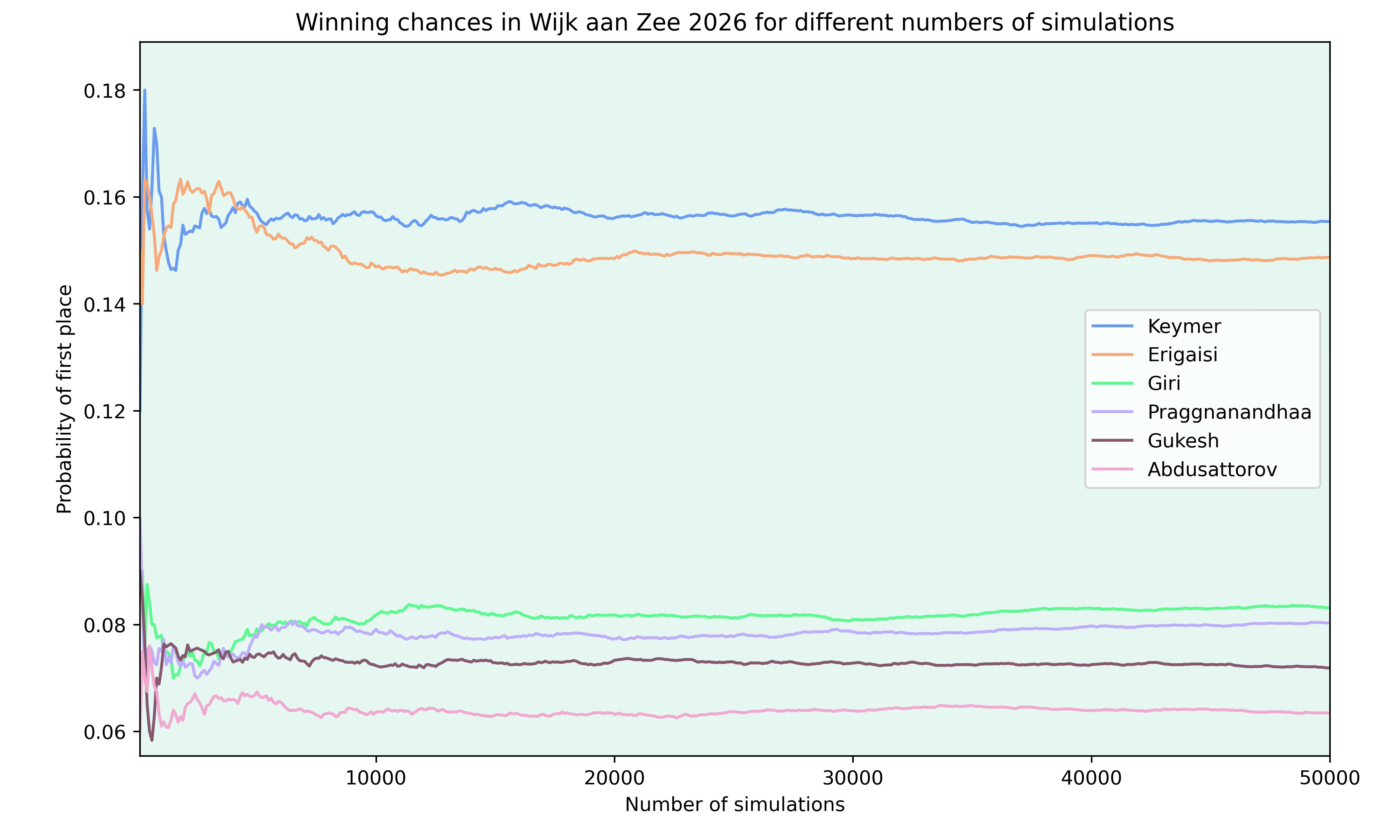
As you can see, the winning chances for each player vary a lot in the beginning, as there just aren’t enough simulations to approach the “correct” value. But after around 20000 simulations, the chances stabilise.
You may also wonder how valid these predictions are, since the eventual winner Abdusattorov is given only a 6% chance to win the tournament. But looking at the probabilities of the players shows why it’s impossible to asses how good the prediction is from a single tournament.
Keymer, as the rating favourite before the tournament, only had a 16% chance to win the tournament, according to my model. This means that there was an 84% chance for him not to win the tournament. So no matter which player would have won, it was always more likely for the player not to win. Also, in this case, the probability of one of the two favourites winning is about the same as one of the players rated 3rd to 6th winning.
To get a bit of an idea of how well the tournament prediction works, I looked at the super tournaments from the past two years and predicted each winner. I got around 20% of the winners correct, while the model had an average probability of 24% for the winner, which is in the same ball park but again, the sample size was pretty low, as there aren’t too many top level tournaments in a year.
But all I’ve talked about so far are predictions before the tournament started. When looking at an ongoing tournament, one can use all finished rounds to improve the predictions as the tournament goes on.
Independence of results
As mentioned earlier, I assumed that all the games in a tournament are independent of each other. This means that the result in a game is unaffected by the results in the previous rounds.
There are some factors that could make the results depend on the games played in the previous rounds of the tournament. Sometimes players appear to be on good or bad shape during a tournament and so they may perform better or worse than expected. However, quantifying this is difficult, as streaks can often be explained by random variation, especially since chess tournaments usually only consist of 9 rounds.
Apart from hot streaks, the tournament situation could also play a role in the outcome of games. But again, it’s difficult to quantify how this will actually impact the outcomes. For example, two players that are out of contention for the tournament win may make a quick draw because the result doesn’t matter anymore or they’ll play with less care, which should lead to more decisive results, because the result doesn’t matter anymore.
I haven’t taken a closer look at how chess tournaments are affected by these factors and if there are reasons to assume that the games aren’t independent. Let me know if you’d be interested in a post about that.
I looked mostly at the independence of results section. I mean I need to read a few of your posts back for the rest, but my curiosity is often about model assumptions explicit or not.
as a question, does assuming all games in a tier tournament are independent as outcome events to each other say that there was not tiered change of context? I might be ignorant of many known things about tournaments.. but my question may still be helpful to both of us in different ways.. (me side learning about the things to know that your response might include, as well as getting more involved in learning about your models, i.e. guide my reading of this series further, etc.. in ignorance, questions, or hypotheses guide us... as we don't know what we ignore).
Maybe there is something about the paired sampling not being itself modeled? so few games for each pairings possible.. seems like a tournament is not a very "dense" set of data.. (being vague).