


Creating Individualised Chess Engines
How well can programs predict moves of individual players?

When looking at chess engines, I always think about ways that players can use them, either to get ideas or to improve at chess. Usually, the idea behind chess engines is to make them as strong as possible. But since they are already so much stronger than humans, an increase in strength often isn't very meaningful to players, especially at the club level.
A couple of years ago, a new engine called Maia was released and the team behind it didn't want to create the strongest engine. Instead, they wanted to create an engine that is best at predicting human moves. And they achieved just that.
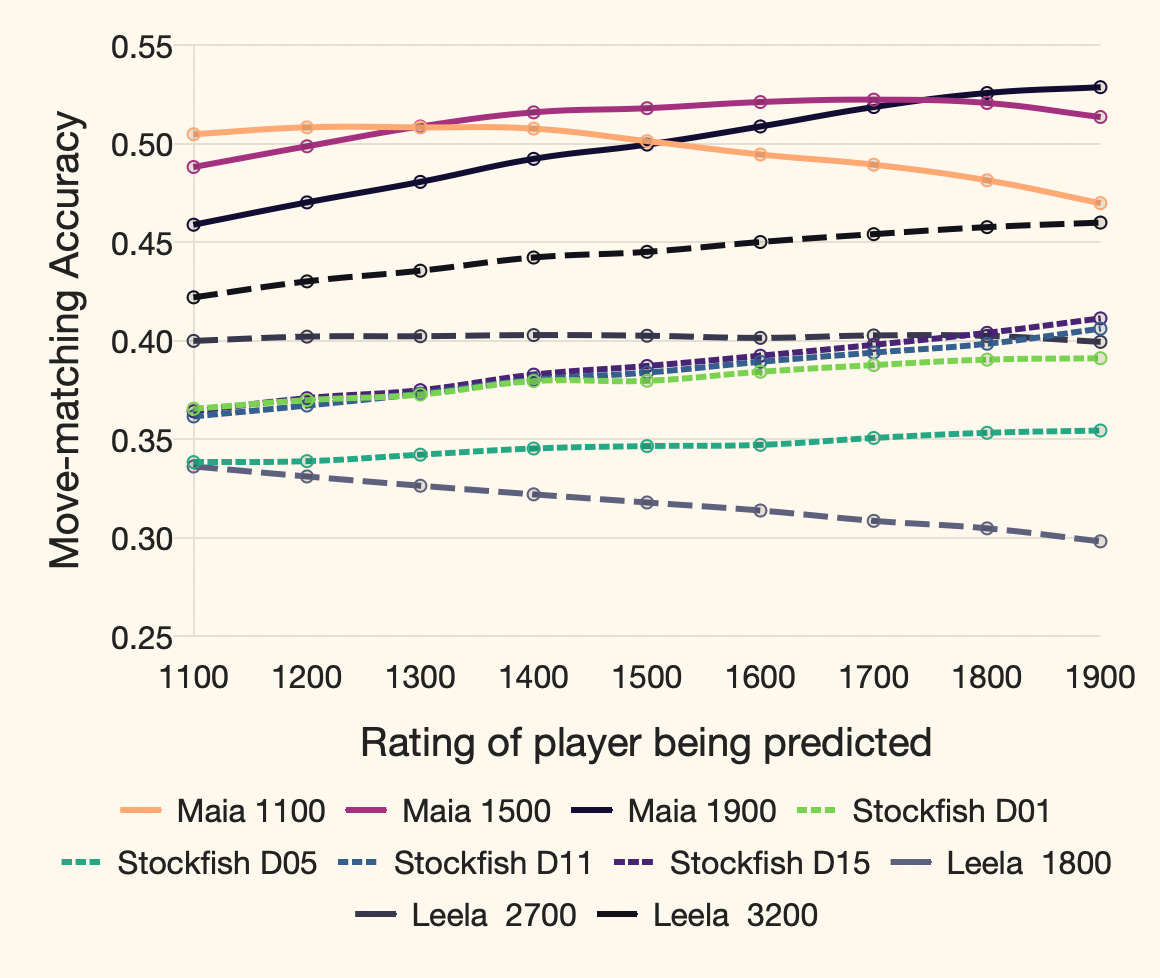
They trained a neural network on games played on Lichess and the model's task was to predict the next human move. To do this, they split the games in 100 point rating bands and trained one model for each band. Each Maia model predicted around 50% of the moves made by humans at a given skill level, which was significantly better than Stockfish or LC0 at various depths.
These models are already very interesting, since they emulate human play at the targeted rating level very well. But after that, they have published even more fascinating chess models.
I recently came across a paper from the same authors from 2022 titled "Learning Models of Individual Behavior in Chess" in which they took a Maia model and individualised it to a specific player. And the results they got are extremely interesting.
They increased the accuracy of the move prediction for a specific player by 4-5%. More impressively, given a sample of 100 games, the model can identify the player who has played them with 98% accuracy out of a pool of 400 players.
Methodology
They started out with the Maia models which were trained to predict human moves at a specific skill level and they specialised them to predict the moves of an individual player. As a baseline they used the Maia 1900 model for all 400 players in their dataset since using the nearest Maia didn't yield any significant improvements.
Their dataset included 400 players with a Lichess rating between 1100 and 2000, each of them having 10,000 or more games in the dataset. They trained different models with various number of games by the players and concluded that the individualised models (called 'Transfer Maia' in the graphs) outperform the baseline Maia if they trained it with at least 5000 games.

5,000 games are a lot, but since they are only looking at online blitz games, it's not unreasonable to have so many games from a single player.
Results
As mentioned above, the individualised model is 4-5% more accurate when predicting the moves of a player.
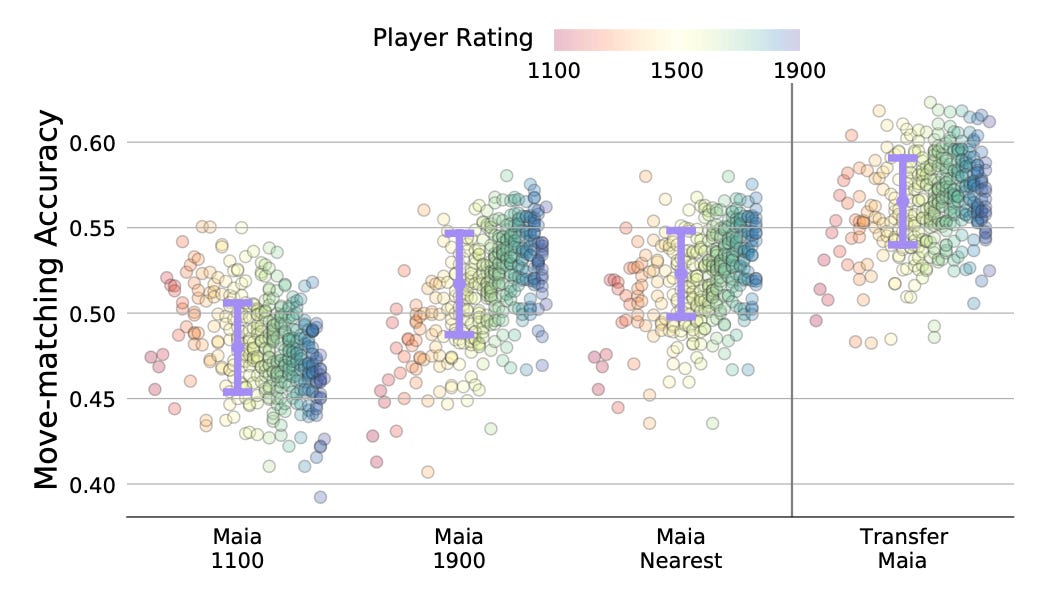
It's also interesting to see how this changes with the accuracy of the move itself. The following graph compares accuracy of the models depending on the "goodness" of the move actually played by the players.
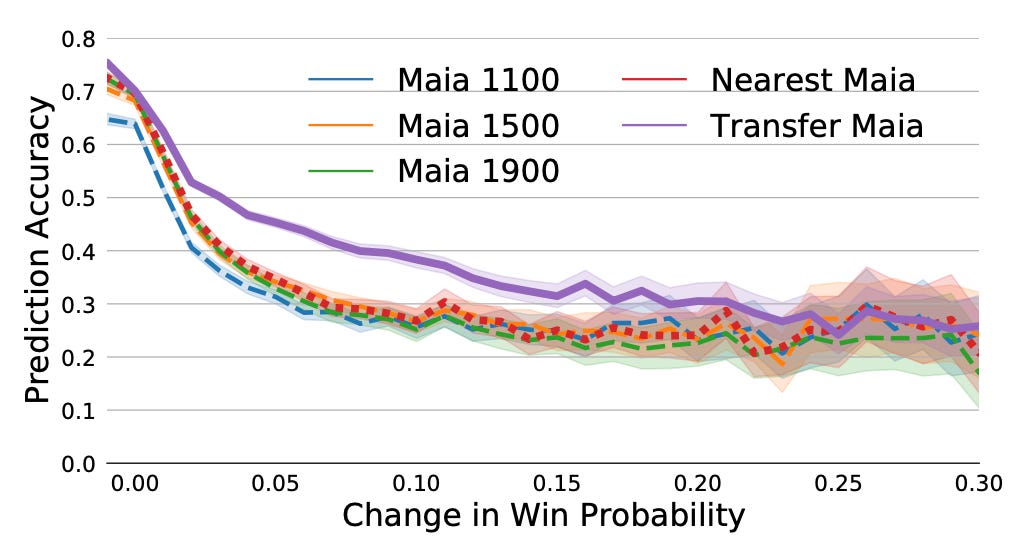
Transfer Maia always performs better than the other Maia models, but it's interesting to see that its advantage increases in situations where the human players made inaccuracies and mistakes. This suggests that mistakes are very individual to a player.
They also made some preliminary attempts to create such models for Grandmasters but these weren't as successful. They speculate that GMs are too strong for the human-oriented Maia models. As we will see in the next section, players are best identified by their mistakes, which would suggest that GMs are harder to identify since they make less mistakes than club players.
Identifying a Player
Another interesting point from the paper was that they used the individualised models to identify which players out of the 400 has played a specific set of games. They did this by letting each model predict the moves of the games and the player corresponding to the model which got the most right predictions was selected as the guess for the who played these games. The authors tested various numbers of games and also started some games only after 10 or 30 ply in order to reduce the impact of openings that the model might have memorised. Their results are summarised in the following table:

In the best case scenario - having 100 games to look at and starting from the first move - they identified the player 98% of the time. And even with only 10 games and starting after move 15 (30 ply), their models still identified the player 11% of the time, which is a significant improvement to the 0.25% which would be the chance for random guessing.
They also test their models only with the mistakes that players have made. The result was that the identification of the player got even slightly better with 98.9%. This suggests that the mistakes a player makes identifies them.
This can have big consequences for chess improvement since such models can identify the types of mistakes that a specific player typically makes, which makes it much easier to work on them. Also since the mistakes are highly individual, they should be easily fixable since other players at a similar skill level don’t make these mistakes.
Creating your own Models
The authors have published their code on on Github, so you can check it out for yourself. I'll certainly look more into it in the future and plan to test various things with such models.
Until then, I would like to hear what you think about it!
Nice post! I really enjoyed it. It occurred to me a few months ago that if a model can be designed to predict the move a particular player would make, then it should be possible to design an engine who plays in the style of that player. Obviously, titled players could derive some competitive advantage from the ability to spar with these simulacra. For example, an engine emulating Ding Liren would be the ideal sparring partner for Gukesh in the upcoming World Chess Championship.
Thanks, Julian.