
Bug Fixes and Zobrist Hashing
Building a Chess Engine - Part 10

Thank you to everyone who played against my bot on Lichess. All these games helped me to find bugs and it was really exciting to see my engine play against other people for the first time. If you want to play it, you can challenge it on Lichess.
Since the last update, I focused on fixing the bugs I saw in the games and implementing some missing features.
Bug Fixes
After seeing the first games by my engine, I noticed that there were a few bugs I didn’t catch before I saw more games. At first it often resigned games because it played illegal moves. The problem was caused by the move ordering, which was sometimes changing moves instead of just reordering them.
After this was fixed, there were still some very strange moves where my engine simply gave up pieces for no reason. After some digging I found that the problem was in the qsearch. The search returned the wrong value when no other move was found.
These two changes helped a lot and my engine was playing much better. But when it tried to convert winning positions I noticed (apart from its terrible endgame technique) that I forgot to implement stalemate. This was quickly fixed, but detecting threefold repetitions was also missing. This was intentional since keeping track of the history of the game is quite tedious. But this is was I tackled last week.
Zobrist Hash
To figure out if a repetition occurs, one has to keep track of all previous positions in the game. This is clearly quite memory intensive, so engines usually store a hash value instead of the entire position. Typically a so-called Zobrist hash is used in chess engines.
This hash function works by associating a 64 bit pseudo-random number to each relevant information in the position: one number for each piece on each square, one number for each possible combination of castling rights, one number for the en-passant square and one number for the side to move. To calculate the Zobrist hash of a position, the random numbers for each element of the position get XOR'd (added) together and the result will be a 64 bit number.
As an example, let's calculate a simplified form of the Zobrist hash with 4 bit for the following study by Alexey Selezniev, 1921:
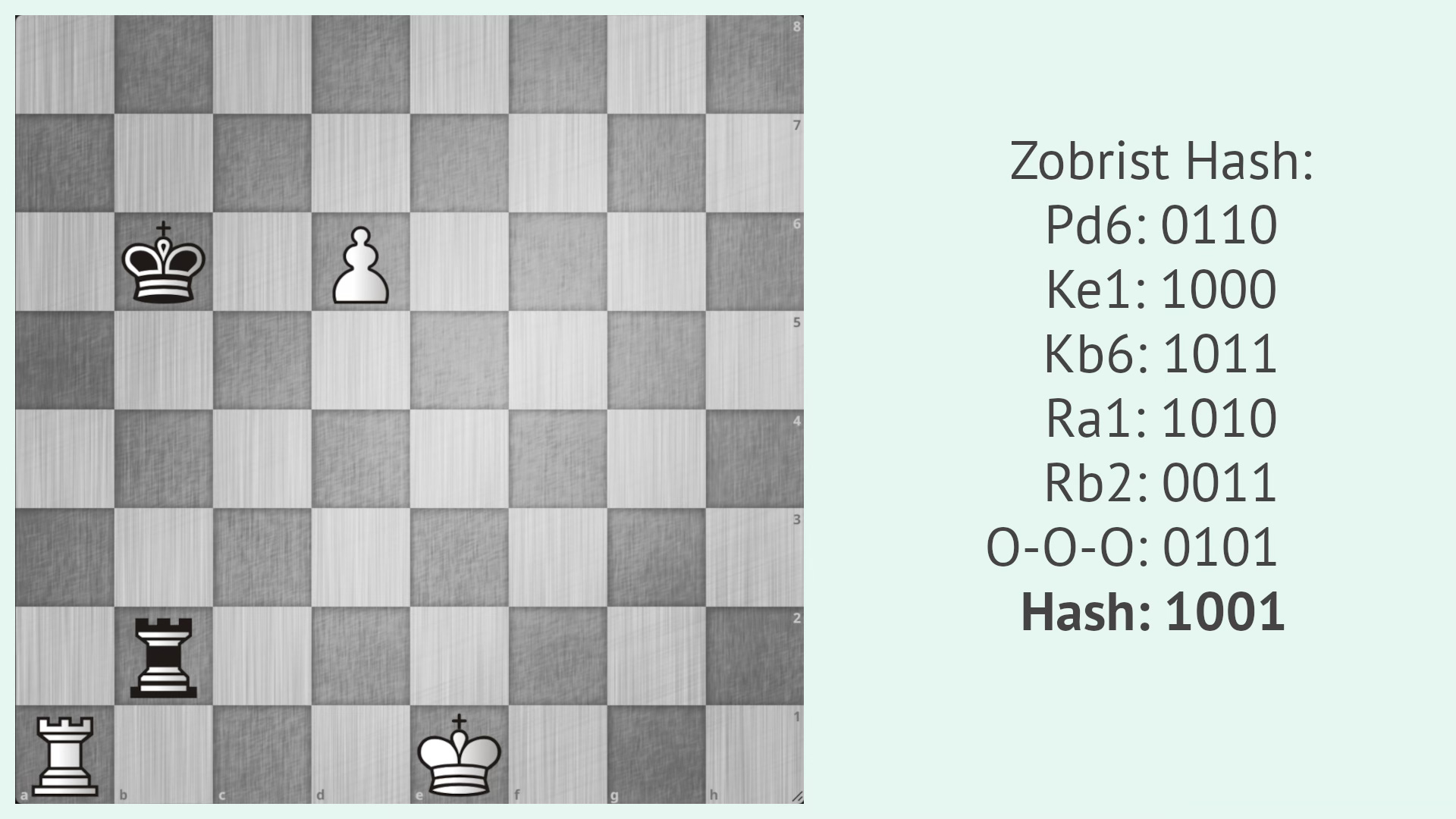
Let's say that a pawn on d6 has the random value 0110 associated to it, the kings on e1 and b6 1000 and 1011, the rooks on a1 and b2 1010 and 0011, and the queenside castling rights have 0101. There is no en-passant square in the position and as it's white to move, we don't add the value associated to black's turn. So simplified Zobrist hash of this position is 1001, which is calculated by taking the XOR of all the values (i.e. binary addition without carry bits, so normal addition with the rule 1+1=0).
Saving only the 64 bit hash is much more efficient since a position in my engine consists of 12 64 bit numbers (one for every piece type), 6 bit for the en-passant square, 4 bit for the castling rights, one bit for the side to move and some additional information for the move numbers. The downside is that as the data gets compressed, different positions can have the same hash value, which is called a hash collision. But with a well-chosen hash function and good random values, this should rarely happen. And even if there is a hash collision, the result would only be that the engine thinks that the position has been repeated one more time.
Optimisation
While saving only the hash of each position saves space compared to saving the whole positions, it's still quite expansive to store one 64 bit number for each ply that has been made. So I needed to optimise the engine a bit further to keep the performance at least on the level it was before I implemented the history.
Firstly I noticed that I could change some uses of positions to pointers, which saved a lot of time especially after the hash has been implemented.
I also changed the functions to generate the legal moves and attack of the pieces. Before they got the whole position as an input but I changed it to only use the relevant bitboards (64 bit numbers). This reduced the amount of data that needed to be moved around and hence made the whole engine faster.
There were also some minor tweaks that had a surprisingly big impact on the performance. Overall the move generation is now around 15% faster than it was before I implemented the hash.
If you're interested in the code, you can check it out here.
Next Steps
While I improved the performance a bit, I didn't increase the search depth of the bot on Lichess, so the strength of the engine should be the same. To increase the depth of the search, some further optimisations are needed, both in the move generation and in the search function. This will be my goal for the next weeks.
The engine is currently also horrible at converting endgames. In winning endgames it often doesn't make any progress since it can't search deep enough to see the mate. I want to fix this by including some heuristics for such endings but only after I improved some of the important underlying bits of the engine.
Kudos for using that study as an example! :)